![shutterstock_155486141]()
In my previous post, I provided some theory on how the cost of fixing a bug increases as it spreads across different environments inside and outside your organisation. Bugs will always try to sneak out of your workspace, contaminating the workspace of your colleagues and eventually they could end up in your customer’s browser. Since bugs are sneaky by nature, we as developers need to apply as many tricks we can to find them early. And here’s the hard part, doing this without spending too much time or resources.
Manual vs Automated testing
You always have the option of verifying that a feature works manually with a few clicks in the browser. This can be done by you as a developer or by a QA team. While a single test cycle using this approach is often the fastest, it does not scale as the number of features grow. Each time you need to manually test, you spend resources – your valuable time. For a commercial SW project, you definitely want to verify your system as often as possible – ideally after every commit, but realistically at least daily. The bigger your application, the bigger your test spec becomes and the more time you will need to spend.
![chart]()
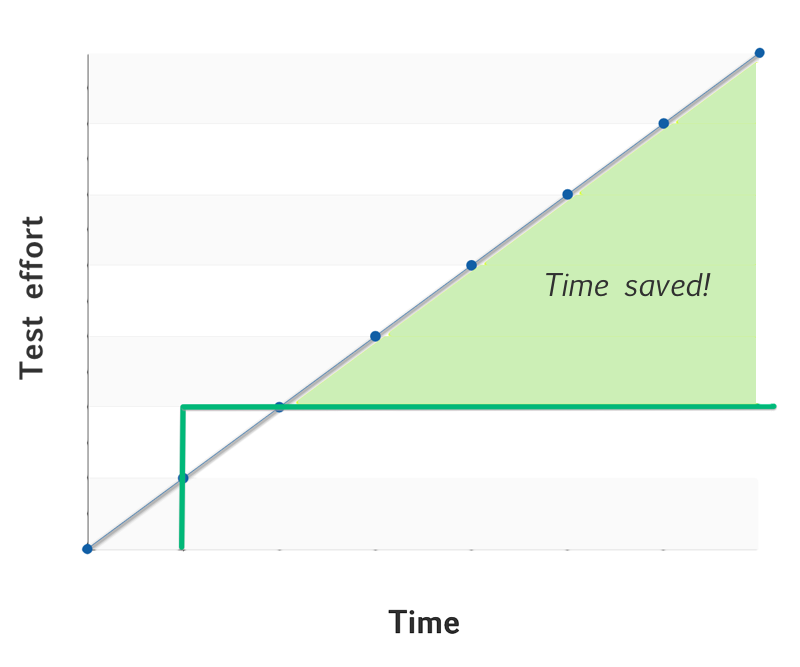
A better way to verify if a feature works is to write a unit test for it. A testing cycle in this approach of course requires some initial effort, definitely more than for one cycle of manual testing. But once written, the test can be automated and launched any number of times at no extra cost – this approach scales. See how the added green line in the chart becomes flat after the initial effort of writing the test, it can then be reused any number of time without extra cost.
![chart2]()
At Bryntum, we rely heavily on automated tests and this allows us to keep all our products in good shape with limited resources.
When should you fight a bug by writing a test?
So you’ve found a bug, how do you determine if it warrants a new test case? You need to prioritize and choose carefully what you test to make sure you are not “overtesting”. Covering every possible use case with a test is not feasible, and will take too much time away from developing your product. Having a too large test suite can also be cumbersome as it will take longer and longer to complete. Speaking from my own experience at Bryntum, here is a list of questions that we use to determine if it’s time to write a new test case.
![]() Will this bug affect a large number of our users?
Will this bug affect a large number of our users?![]() Has this bug been reported before?
Has this bug been reported before? ![]() For online sample bugs, could the bug impact sales?
For online sample bugs, could the bug impact sales? ![]() Can a test be easily written in < 10 minutes?
Can a test be easily written in < 10 minutes?![]() Did the bug take a lot of time and energy to investigate?
Did the bug take a lot of time and energy to investigate?
This list is not exhaustive and will of course vary from business to business.
Finding bugs.
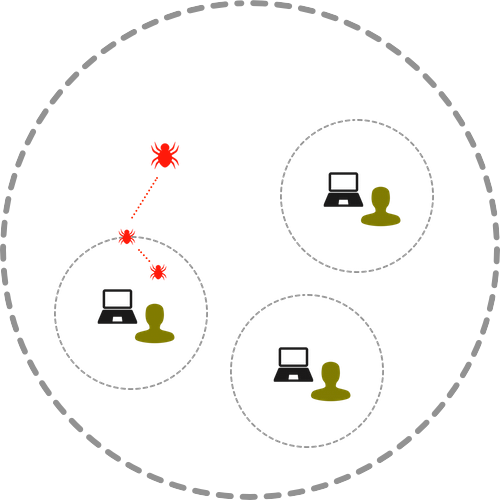
If you recall the different tiers from part 1, these are the environments where you can catch bugs in your product lifecycle.
- 1. Your development machine
- 2. Your team
- 3. Your organization
- 4. Your customer (developers just like you)
- 5. Your customer’s customer – the end users
For these tiers, lets examine the solutions we use at Bryntum.
Tier 1 – Your development machine. The pre-commit hook
The earliest time you can find a bug is on your own machine. Once you have a decent test suite, you can run a few smoke tests prior to committing your code to the repo. This is a great way to keep the build green and developers motivated. Nothing demoralizes a dev team like a broken build. The pre-commit should at a minimum do the following:
- 1. Verify syntax is correct. JsHint is great for this.
- 2. Find forgotten
debugger or console.log statements, as well as t.iit test
statements (very easy to forget in your tests)
- 3. Run a few select smoke tests
The smoke tests should focus on preventing the most simple errors and it should also assure that the most critical parts of your codebase are ok. These smoke tests should run fast, fast, fast. This is not the place to run all your advanced UI tests, that will simply take too long. We use the awesome PhantomJS to run a subset of all our unit tests (which are not DOM related) along with a few UI tests. All in all, this pre-commit takes around 10 seconds and keeps our source repo in good shape. Here’s our current pre-commit hook:
#!/bin/bash
# 1. Run JsHint
# ----------------------
jshint $(git diff --cached --name-only --diff-filter=ACMRTUXB | while IFS= read -r line; do
if [[ $line =~ ^js\/.*\.js$ ]]; then
echo $line
fi
done)
if [ "$?" != "0" ]; then
exit 1
fi
echo "JSHint sanity test passed correctly"
# passthrough the exit status of the failed pipe subshells
set -o pipefail
# 2. Look for forgotten t.iit statements in tests
# ----------------------
git diff --cached --name-only --diff-filter=ACMRTUXB | while IFS= read -r line; do
if [[ $line =~ ^tests\/.*\.t\.js$ ]]; then
cat $line | grep -q '.iit('
if [ $? == "0" ]; then
echo "t.iit() statement found in file: $line"
# will exit a pipe-subshell only, need additional check below
exit 1
fi
fi
done
if [ "$?" != "0" ]; then
exit 1
fi
echo "No t.iit statements found"
# 3. Run smoke tests
# ----------------------
../siesta/bin/phantomjs http://lh/ExtScheduler2.x/tests/index-no-ui.html?smoke=1 --pause 0 --no-color
exit $?
Once you’re happy setting up your pre-commit hook, you should also ensure that everyone uses it. We do this by adding an extra step in our build script, which copies the pre-commit file into the .git folder. This way we know all developers share the same hook.
# install the pre-commit hook
cp build/pre-commit .git/hooks/
Tier 2 – Your team. The automated test suite
The pre-commit hook is a great tool for preventing bugs from sneaking out of your development machine, but the best weapon by far for finding bugs is an automated test suite. The test suite covering your JavaScript code base should ideally be executed at least once per day in all the browsers you support. At Bryntum we test all products nightly, in IE8/9/10, Chrome, Firefox and Safari. In the morning when our developers start their work, they already have an email in their inbox with the most recent results. Broken tests have the highest priority for us, as they indicate something is broken in the product which means we cannot ship.
Monkey love
![shutterstock_33253210]()
As I mentioned earlier, since bugs are sneaky creatures you need to apply every trick you have against them. One testing concept that I’m a big fan of is Monkey testing, which means simulating random input to the UI and observing what happens. As part of testing our Ext Scheduler product and running our nightly build, we monkey test each of of our 45+ examples which over the years has found us many many bugs, for free. Let me repeat that using a larger font.
FOR FREE
This is naturally a huge help for a small company like us with limited resources. Here’s the test we use to make sure our examples render and do not produce any exceptions when attacked by a hoard of monkeys.
t.waitForSelector('.sch-timetd', function() {
t.pass('Scheduler example rendered without exception');
t.monkeyTest('>>schedulerpanel', 10);
});
The ROI here is enormous, we write one simple t.monkeyTest statement and magic bug-hunting monkeys appear. What more can you ask for, really? In the line above, “>> schedulerpanel” means a Component Query matching “schedulerpanel”, and the second argument (10) specifies how many random actions (clicks, types, drags etc) should be performed.
Tier 3 – Your organization
Just as monkey testing helps us find bugs for free, we can make use of the visitors trying the live examples on our site. When someone is clicking around in our samples and an exception is thrown – we can know about it easily using a window.onerror hook. We do this for all of our online samples and it has also allowed us to find quite a few bugs for free (although at a much later stage than the monkeys). Each time an exception is thrown in one of our online examples, the following information is gathered and emailed to our developers:
Message: Uncaught TypeError: Cannot call method 'disable' of null
Url: http://www.bryntum.com/examples/gantt-latest/examples/advanced/js/Toolbar.js?_dc=1390056859111
Line: 12
Href: http://www.bryntum.com/examples/gantt-latest/examples/advanced/advanced.html
Browser: Chrome32
Product version: 2.2.16
Local date: Sat Jan 18 2014 21:55:11 GMT+0700 (SE Asia Standard Time)
As you can see above, we collect the error message, browser + version and also the local date which can be useful information in case the bug is related to a certain timezone.
Tier 4 and 5 – Your customer and end users
If a bug has reached these tiers, it is out of your control. It is important to have a clear and efficient procedure for resolution of such bugs. At Bryntum we use a bug tracker tool by Assembla: https://www.assembla.com/spaces/bryntum/support/tickets. This tool allows us to communicate efficiently with the bug reporter and provides transparency for our customers.
We should also mention that it’s not enough to simply fix the bug. It is equally important to deliver a patch to the customer. For this purpose we use a rapid development cycle and our release cycle is usually about 2-3 weeks. If a critical bug is found, it is fixed (along with a new test of course) and a new release is initiated. Additionally, we also publish our nightly builds which means our customers can verify a bug fix the day after a bug has been corrected.
A real world story
Here’s a typical example of one Bryntum bug life cycle, which starts at tier 4.
A week or two ago, a bug report was filed about the resizing of tasks in Ext Scheduler under certain circumstances (Ticket status – New). It turned out, after a bit of manual testing that if you were changing the duration of a task and just moved the mouse a few pixels, the resize operation behaved weirdly and exceptions were seen. (Ticket status – Accepted). Since the Scheduler fires events at different stages during a resize operation, my guess was that the operation wasn’t finalized properly. This turned out to be correct. I assigned this bug to myself and wrote a test, since I felt the resize feature is quite important for every user and it would be very easy to test (see point 4 in the list above). Here’s the extremely simple test I wrote which took less than 5 minutes to write:
t.it('Should finalize if mouse only moves a little', function(t) {
var scheduler = t.getScheduler({
renderTo : Ext.getBody(),
height : 200
});
t.firesOnce(scheduler, 'beforeeventresize')
t.firesOnce(scheduler, 'eventresizestart')
t.firesOnce(scheduler, 'eventresizeend')
t.chain(
{ waitFor : 'eventsToRender', args : scheduler },
{ drag : '.sch-resizable-handle-end', by : [3, 0] }
);
});
Note the use of our convenience method getScheduler which helps us reduce the amount of boilerplate test code. As I ran the test, this is what I saw in my WebStorm output window.
run-phantom lh/ExtScheduler2.x/tests/index-no-ui.html --filter 062_resize.t.js --pause 0
fail 4 - Observable fired expected number of `eventresizeend` events
Failed assertion `firesOk` at line 139 of event/062_resize.t.js?Ext=4.2.1
Actual number of events : 0
Expected number of events : 1
[FAIL] event/062_resize.t.js?Ext=4.2.2
3 passed, 1 failed assertions took 0.983s to complete
And that’s the proof I needed, the eventresizeend was not fired in this case. After adding a simple fix for this case in our source code, the test turned green and I could no longer reproduce the issue (Ticket status – Resolved).
Note, that from this point, if this bug were to ever appear again in our product – it would be caught by our test suite in Tier 2 without any additional effort from me.
That’s it for part 2…
In this post I’ve mentioned a few tricks and habits we employ at Bryntum to make sure we find bugs as early as we can and ship high quality software. In the next part of this series, we’ll look at the Continuous Integration side of things and how our nightly builds work.